No universo de Data Center, existe uma regra não escrita: quando a rede e a virtualização se encontram, o diabo mora nos detalhes da configuração. Recentemente, um colega de infraestrutura de outra empresa entrou em contato com um problema que estava tirando o sono da equipe: uma lentidão extrema durante as migrações de máquinas virtuais.
O cenário era clássico. Hosts VMware conectados a switches Cisco Nexus. O sintoma? Toda vez que ocorria um vMotion, o que deveria ser um processo transparente com delay na casa dos microsegundos se transformava em uma queda de conectividade, com o delay da VM saltando para mais de 1 segundo, gerando perdas de ping intermitentes.
E é aí que começa o nosso troubleshooting.
A Primeira Pista: O Log do Nexus e o Spanning Tree
Sem acesso direto ao ambiente, a investigação começou com a análise dos logs e das configurações do Cisco Nexus. Logo de cara, os logs de debug do processo STP ([stp] E_DEBUG) mostravam uma agitação incomum. O Rapid Spanning Tree estava constantemente reinicializando o estado de algumas portas.
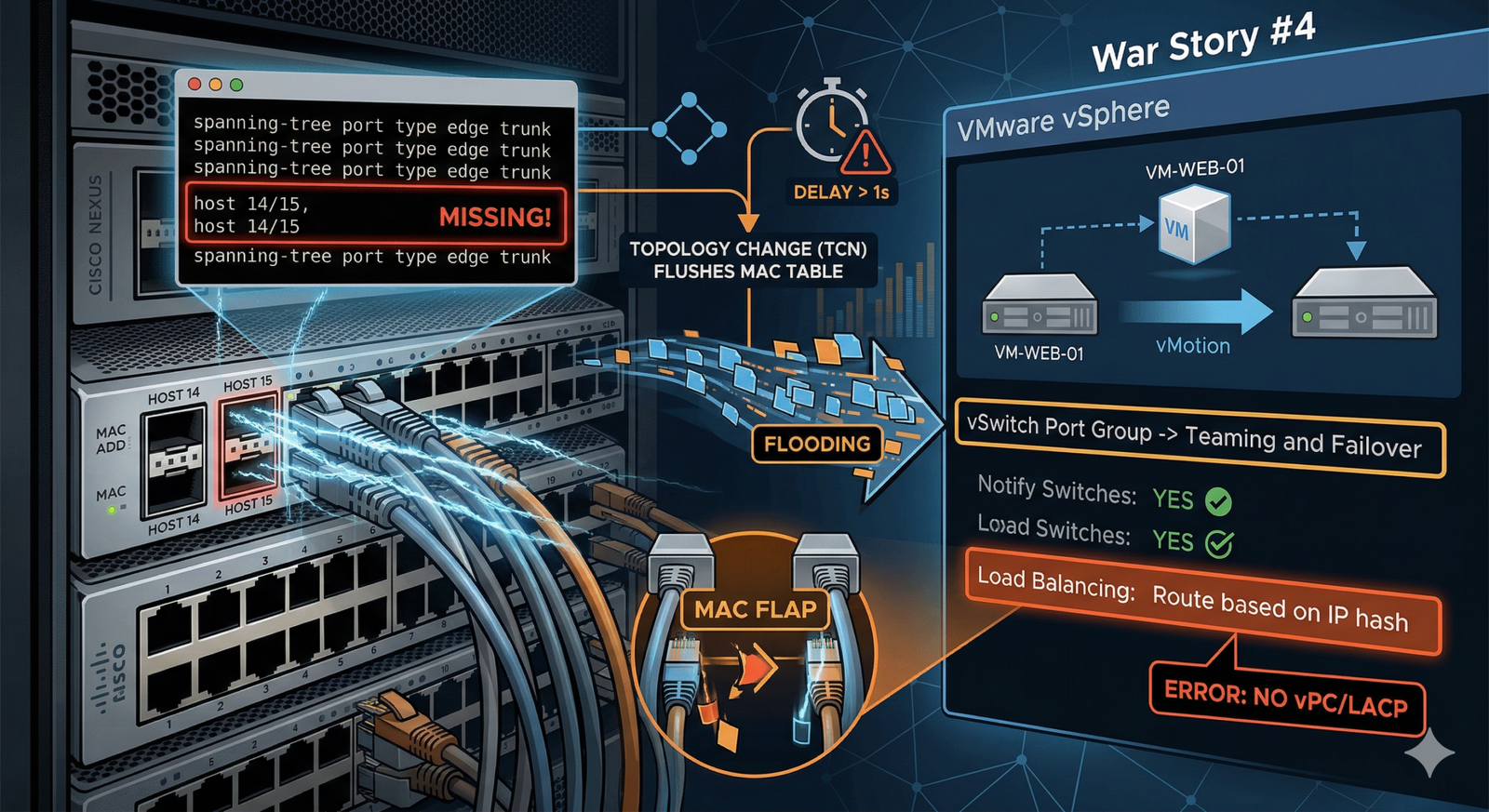
Ao cruzar essa informação com o show running-config das interfaces, a raiz do problema (na camada 2) saltou aos olhos. As portas que conectavam a maioria dos hosts ESXi estavam perfeitamente configuradas com o comando de borda:
Cisco CLI
spanning-tree port type edge trunk
No entanto, nas portas dos hosts mais recentes (do ESXi 14 e 15), esse comando havia sido esquecido. Elas estavam configuradas apenas como trunks normais.
Por que isso derruba a performance? Quando um switch Nexus percebe a porta sofrendo um flap ou uma mudança abrupta de MAC (como ocorre quando a VM “pula” para o novo host no vMotion), e essa porta não é designada como edge, o switch trata aquilo como uma alteração na topologia da rede. Ele gera um TCN (Topology Change Notification). Esse TCN força a rede inteira a dar um “flush” na tabela de endereços MAC. O switch esquece onde os dispositivos estão e precisa re-aprender tudo, gerando uma tempestade de pacotes (flooding) que afoga a rede momentaneamente.
O conselho imediato foi: padronizar as portas novas aplicando o edge trunk. Problema resolvido, certo? Errado.
O Plot Twist: Quando a Rede Resolve, mas o Ping não Volta
O colega aplicou a configuração de borda, eliminou os TCNs, mas o problema persistiu. O vMotion acontecia rápido, as placas de rede dedicadas de 25Gbps mostravam que não havia gargalo de banda, mas o ping da VM continuava falhando após a migração.
Quando o switch está bem configurado e o problema persiste na transição do MAC, a investigação precisa subir uma camada e olhar para dentro do vCenter. Entramos na fase 2 do troubleshooting, focando em duas configurações críticas do vSwitch:
Suspeito 1: Notify Switches
No VMware, dentro das políticas de Teaming and Failover do Port Group, existe a opção Notify Switches. Se ela estiver marcada como “No”, o hypervisor não envia o pacote RARP (Reverse ARP) para avisar o Nexus que a VM mudou de porta. Resultado: o switch continua mandando os pacotes da VM para a porta do host antigo até que a tabela MAC expire naturalmente. O colega validou e, felizmente, estava como “Yes”. O MAC estava atualizando instantaneamente no Nexus.
Suspeito 2: A Política de Load Balancing (O Culpado)
Se o switch aprende o MAC novo rápido, mas o ping fica intermitente, isso cheira a MAC Flapping. Ao analisar o design físico, os cabos dos hosts ESXi desciam para o Nexus como portas de acesso independentes em modo trunk (sem formar um Port-Channel / vPC).
Nesse cenário, o VMware obrigatoriamente precisa usar a política de balanceamento de carga padrão: Route based on originating virtual port. Se alguém, na tentativa de otimizar o ambiente, alterou essa política para Route based on IP hash sem configurar um Link Aggregation (LACP) no switch físico correspondente, o caos se instala. O VMware começa a espalhar os pacotes de origem da mesma VM pelos dois cabos físicos. O Nexus recebe o mesmo MAC address piscando em duas interfaces diferentes, interpreta isso como um loop e começa a dropar o tráfego intermitentemente.
A Lição do Dia
Essa war story é um lembrete valioso para quem trabalha com Data Centers. A linha que divide a rede física da virtualização é invisível para os pacotes. Um simples comando esquecido no CLI de um Nexus ou uma política de Teaming agressiva no vCenter podem colocar um ambiente inteiro de joelhos.
O troubleshooting moderno exige olhar para o todo. Não basta provar que “a rede está normal”; é preciso entender como o hypervisor conversa com o silício do switch.
E você, já pegou alguma bucha parecida envolvendo hypervisors e switches no seu ambiente? Deixa aí nos comentários!
Autor
edgarrodrigues100@yahoo.com.br
Posts relacionados
War Story 08: Troubleshooting de Multi-Pod Bring-up (Back-to-Back) – Da Análise de Logs à Consistência da MIT
Contexto de Atuação: Fui acionado neste projeto para atuar de forma independente no papel de auditoria técnica e malha de segurança. Minha...
Leia tudo
War Stories #07: O Mistério do Contrato Liberado: Quando a TCAM diz “Sim” e o Packet-Log diz “Não” (O Efeito QUIC no Cisco ACI)
Imagine a cena: uma tarde tranquila na operação de infraestrutura de rede. Você acabou de implementar ou validar uma regra de acesso...
Leia tudo
War Stories #06: O Bloqueio Fantasma de SSH Pós-Upgrade no Cisco ACI 6.x
A janela de manutenção (Gemud) está na reta final. O cluster APIC atualizou e está cravado como Fully Fit. Os switches Spines...
Leia tudo
War Stories #05: O Assassino Silencioso do Upgrade para o Cisco ACI 6.x
Quem opera Data Centers sabe que uma Gemud de atualização do Cisco ACI nunca é apenas um “Next, Next, Finish”. O Fabric...
Leia tudo
War Story #03 | O Túnel SD-WAN Fantasma e a Ilusão da Interface Gráfica
Toca o alerta para entrar numa sala de guerra. O cenário relatado: o Hub SD-WAN (Viptela) precisava alcançar o Firewall de Internet....
Leia tudo
War Stories #02 | O Caso das iLOs “Mudas”: Por que o Hardware Proxy derrubou o acesso?
Na engenharia de redes, o problema mais difícil de resolver não é aquele que “está tudo parado”, mas aquele que “funciona às...
Leia tudo